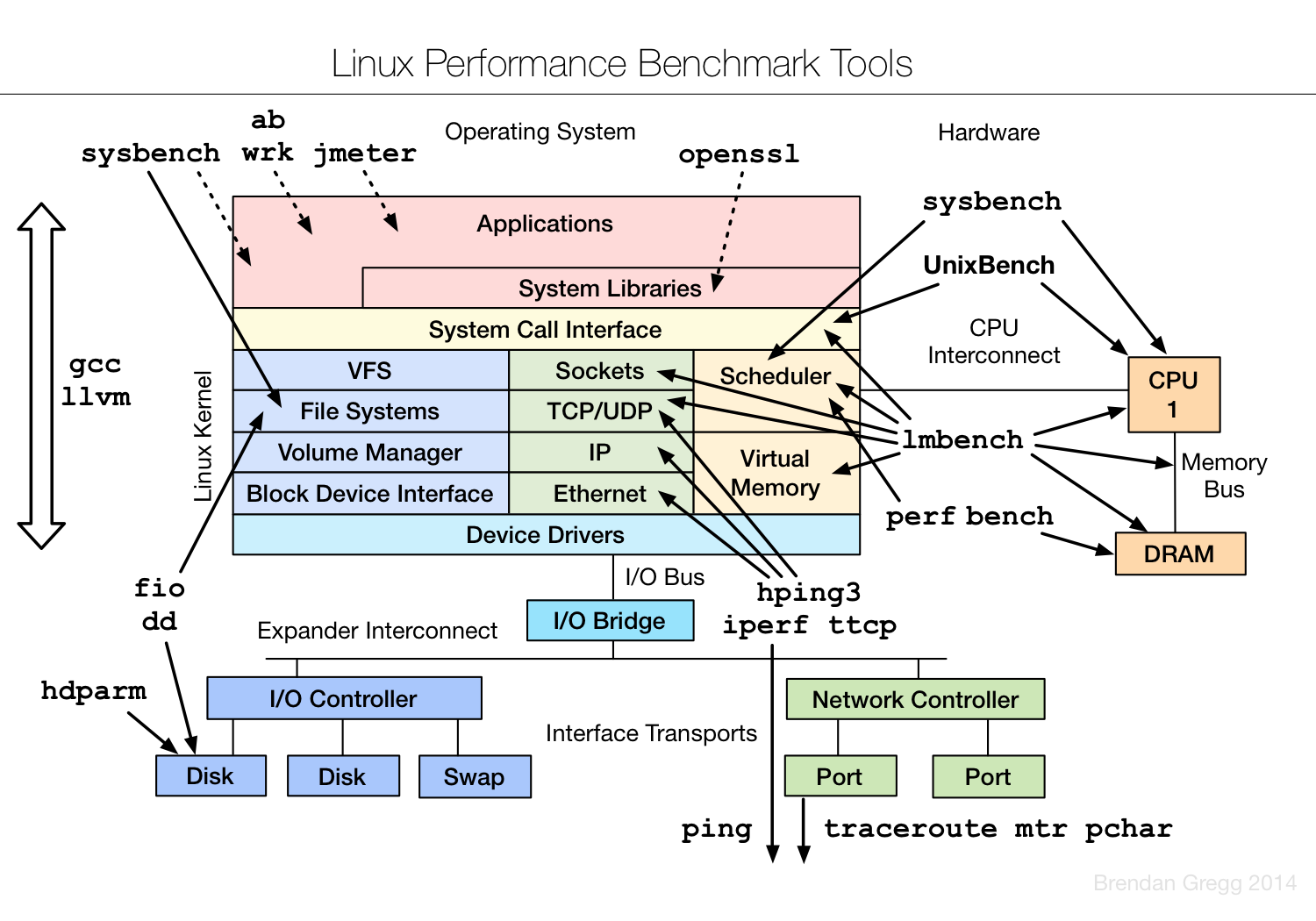
From http://blog.charlee.li/bash-pitfalls/
感谢fcicq,他的new 30 days系列为我们带来了不少好文章。
今天想分析的是这篇Bash Pitfalls, 介绍了一些bash编程中的经典错误。fcicq说可能不适
合初学者,而我认为, 正是bash编程的初学者才应该好好阅读一下这篇文章。
下面就逐个分析一下这篇文章中提到的错误。不是完全的翻译,有些没用的话就略过了,
有些地方则加了些注释。
常见的错误写法:
for i in `ls *.mp3`; do # Wrong!
为什么错误呢?因为for…in语句是按照空白来分词的,包含空格的文件名会被拆成多个词。
如遇到 01 - Don’t Eat the Yellow Snow.mp3 时,i的值会依次取 01,-,Don’t,等等。
用双引号也不行,它会将ls *.mp3的全部结果当成一个词来处理。
for i in "`ls *.mp3`"; do # Wrong!
正确的写法是
for i in *.mp3; do
这句话基本上正确,但同样有空格分词的问题。所以应当用双引号:
cp "$file" "$target"
但是如果凑巧文件名以 - 开头,这个文件名会被 cp 当作命令行选项来处理,依旧很头疼。
可以试试下面这个。
cp -- "$file" "$target"
运气差点的再碰上一个不支持 – 选项的系统,那只能用下面的方法了:使每个变量都以目录开头。
for i in ./*.mp3; do
cp "$i" /target
...
当$foo为空时,上面的命令就变成了
[ = "bar" ]
类似地,当$foo包含空格时:
[ multiple words here = "bar" ]
两者都会出错。所以应当用双引号将变量括起来:
[ "$foo" = bar ] # 几乎完美了。
但是当$foo以 - 开头时依然会有问题。 在较新的bash中你可以用下面的方法来代替,
[[ 关键字能正确处理空白、空格、带横线等问题。
[[ $foo = bar ]] # 正确
旧版本bash中可以用这个技巧(虽然不好理解):
[ x"$foo" = xbar ] # 正确
或者干脆把变量放在右边,因为 [ 命令的等号右边即使是空白或是横线开头,依然能正常
工作。 (Java编程风格中也有类似的做法,虽然目的不一样。)
[ bar = "$foo" ] # 正确
同样也存在空格问题。那么加上引号吧。
cd "`dirname "$f"`"
问题来了,是不是写错了?由于双引号的嵌套,你会认为dirname 是第一个字符串,是
第二个字符串。 错了,那是C语言。在bash中,命令替换(反引号``中的内容)里面的双引
号会被正确地匹配到一起, 不用特意去转义。
$()语法也相同,如下面的写法是正确的。
cd "$(dirname "$f")"
- 5.
[ "$foo" = bar && "$bar" = foo ]
[ 中不能使用 && 符号!因为 [ 的实质是 test 命令,&& 会把这一行分成两个命令的。应
该用以下的写法。
[ bar = "$foo" -a foo = "$bar" ] # Right!
[ bar = "$foo" ] && [ foo = "$bar" ] # Also right!
[[ $foo = bar && $bar = foo ]] # Also right!
很可惜 [[ 只适用于字符串,不能做数字比较。数字比较应当这样写:
(( $foo > 7 ))
或者用经典的写法:
[ $foo -gt 7 ]
但上述使用 -gt 的写法有个问题,那就是当 $foo 不是数字时就会出错。你必须做好类型检验。
这样写也行。
[[ $foo -gt 7 ]]
- 7.
grep foo bar | while read line; do ((count++)); done
这行代码数出bar文件中包含foo的行数,虽然很麻烦(等同于grep -c foo bar或者 grep
foo bar | wc -l)。 乍一看没有问题,但执行之后count变量却没有值。因为管道中的每
个命令都放到一个新的子shell中执行, 所以子shell中定义的count变量无法传递出来。
初学者常犯的错误,就是将 if 语句后面的 [ 当作if语法的一部分。实际上它是一个命令
,相当于 test 命令, 而不是 if 语法。这一点C程序员特别应当注意。
if 会将 if 到 then 之间的所有命令的返回值当作判断条件。因此上面的语句应当写成
if grep foo myfile > /dev/null; then
同样,[ 是个命令,不是 if 语句的一部分,所以要注意空格。
if [ bar = "$foo" ]
- 10.
if [ [ a = b ] && [ c = d ] ]
同样的问题,[ 不是 if 语句的一部分,当然也不是改变逻辑判断的括号。它是一个命令。
可能C程序员比较容易犯这个错误?
if [ a = b ] && [ c = d ] # 正确
- 11.
cat file | sed s/foo/bar/ > file
你不能在同一条管道操作中同时读写一个文件。根据管道的实现方式,file要么被截断成0
字节,要么会无限增长直到填满整个硬盘。 如果想改变原文件的内容,只能先将输出写到
临时文件中再用mv命令。
sed 's/foo/bar/g' file > tmpfile && mv tmpfile file
这句话还有什么错误码?一般来说是正确的,但下面的例子就有问题了。
MSG="Please enter a file name of the form *.zip"
echo $MSG # 错误!
如果恰巧当前目录下有zip文件,就会显示成
Please enter a file name of the form freenfss.zip lw35nfss.zip
所以即使是echo也别忘记给变量加引号。
变量赋值时无需加 $ 符号——这不是Perl或PHP。
变量赋值时等号两侧不能加空格——这不是C语言。
here document是个好东西,它可以输出成段的文字而不用加引号也不用考虑换行符的处理
问题。 不过here document输出时应当使用cat而不是echo。
# This is wrong:
echo <<EOF
Hello world
EOF
# This is right:
cat <<EOF
Hello world
EOF
原文的意思是,这条基本上正确,但使用者的目的是要将 -c ‘some command’ 传给shell。
而恰好 su 有个 -c 参数,所以su 只会将 ‘some command’ 传给shell。所以应该这么写:
su root -c 'some command'
但是在我的平台上,man su 的结果中关于 -c 的解释为
-c, --commmand=COMMAND
pass a single COMMAND to the shell with -c
也就是说,-c ‘some command’ 同样会将 -c ‘some command’ 这样一个字符串传递给shell
, 和这条就不符合了。不管怎样,先将这一条写在这里吧。
cd有可能会出错,出错后 bar 命令就会在你预想不到的目录里执行了。所以一定要记得判断cd的返回值。
cd /foo && bar
如果你要根据cd的返回值执行多条命令,可以用 ||。
cd /foo || exit 1;
bar
baz
关于目录的一点题外话,假设你要在shell程序中频繁变换工作目录,如下面的代码:
find ... -type d | while read subdir; do
cd "$subdir" && whatever && ... && cd -
done
不如这样写:
find ... -type d | while read subdir; do
(cd "$subdir" && whatever && ...)
done
括号会强制启动一个子shell,这样在这个子shell中改变工作目录不会影响父shell(执行
这个脚本的shell), 就可以省掉cd - 的麻烦。
你也可以灵活运用 pushd、popd、dirs 等命令来控制工作目录。
[ 命令中不能用 ==,应当写成
[ bar = "$foo" ] && echo yes
[[ bar == $foo ]] && echo yes
- 19.
for i in {1..10}; do ./something &; done
& 后面不应该再放 ; ,因为 & 已经起到了语句分隔符的作用,无需再用;。
for i in {1..10}; do ./something & done
有人喜欢用这种格式来代替 if…then…else 结构,但其实并不完全一样。如果cmd2返回
一个非真值,那么cmd3则会被执行。 所以还是老老实实地用 if cmd1; then cmd2; else
cmd3 为好。
- 21.UTF-8的BOM(Byte-Order Marks)问题
UTF-8编码可以在文件开头用几个字节来表示编码的字节顺序,这几个字节称为BOM。但Unix
格式的UTF-8编码不需要BOM。 多余的BOM会影响shell解析,特别是开头的 #!/bin/sh 之类
的指令将会无法识别。
MS-DOS格式的换行符(CRLF)也存在同样的问题。如果你将shell程序保存成DOS格式,脚本就无法执行了。
$ ./dos
-bash: ./dos: /bin/sh^M: bad interpreter: No such file or directory
交互执行这条命令会产生以下的错误:
-bash: !": event not found
因为 !” 会被当作命令行历史替换的符号来处理。不过在shell脚本中没有这样的问题。
不幸的是,你无法使用转义符来转义!:
$ echo "hi\!"
hi\!
解决方案之一,使用单引号,即
$ echo 'Hello, world!'
如果你必须使用双引号,可以试试通过 set +H 来取消命令行历史替换。
set +H
echo "Hello, world!"
$*表示所有命令行参数,所以你可能想这样写来逐个处理参数,但参数中包含空格时就会失败。如:
#!/bin/bash
# Incorrect version
for x in $*; do
echo "parameter: '$x'"
done
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg'
parameter: '1'
parameter: 'arg2'
parameter: 'arg3'
正确的方法是使用 $@。
#!/bin/bash
# Correct version
for x in "$@"; do
echo "parameter: '$x'"
done
$ ./myscript 'arg 1' arg2 arg3
parameter: 'arg 1'
parameter: 'arg2'
parameter: 'arg3'
在 bash 的手册中对 $* 和 $@ 的说明如下:
* Expands to the positional parameters, starting from one.
When the expansion occurs within double quotes, it
expands to a single word with the value of each parameter
separated by the first character of the IFS special variable.
That is, "$*" is equivalent to "$1c$2c...",
@ Expands to the positional parameters, starting from one.
When the expansion occurs within double quotes, each
parameter expands to a separate word. That is, "$@"
is equivalent to "$1" "$2" ...
可见,不加引号时 $ 和 $@ 是相同的,但$ 会被扩展成一个字符串,而 $@ 会 被扩展成每一个参数。
在bash中没有问题,但其他shell中有可能出错。不要把 function 和括号一起使用。 最为
保险的做法是使用括号,即
foo() {
...
}